/* 清空字典 */ /* Reset an hashtable already initialized with ht_init(). * NOTE: This function should only called by ht_destroy(). */ staticvoid _dictReset(dict *ht) { ht->table = NULL; ht->size = 0; ht->sizemask = 0; ht->used = 0; }
/* Expand the hash table if needed */ staticint _dictExpandIfNeeded(dict *ht) { /* If the hash table is empty expand it to the intial size, * if the table is "full" dobule its size. */ if (ht->size == 0) return dictExpand(ht, DICT_HT_INITIAL_SIZE); if (ht->used == ht->size) /* 哈希表已满,将其容量扩大为原来的二倍 */ return dictExpand(ht, ht->size*2); return DICT_OK; }
/* 哈希表的容量是2的指数次方 */ /* Our hash table capability is a power of two */ staticunsignedlong _dictNextPower(unsignedlong size) { unsignedlong i = DICT_HT_INITIAL_SIZE; /* LONG_MAX定义在limit.h中,指定long类型的最大值 */ if (size >= LONG_MAX) return LONG_MAX; while(1) { /* 但是size是unsigned long */ if (i >= size) /* 所以是否应该与ULONG_MAX比较 */ return i; i *= 2; } }
/* 给定键,若键在哈希表中不存在,返回一个空槽的索引,若已存在,出错 */ /* Returns the index of a free slot that can be populated with * an hash entry for the given 'key'. * If the key already exists, -1 is returned. */ staticint _dictKeyIndex(dict *ht, constvoid *key) { unsignedint h; dictEntry *he;
/* Expand the hashtable if needed */ if (_dictExpandIfNeeded(ht) == DICT_ERR) return1; /* Compute the key hash value */ h = dictHashKey(ht, key) & ht->sizemask; /* Search if this slot does not already contain the given key */ he = ht->table[h]; while(he) { if (dictCompareHashKeys(ht, key, he->key)) return -1; he = he->next; } return h; }
/* Identity hash function for integer keys */ unsignedintdictIdentityHashFunction(unsignedint key) { return key; }
/* Generic hash function (a popular one from Bernstein). * I tested a few and this was the best. */ unsignedintdictGenHashFunction(constunsignedchar *buf, int len){ unsignedint hash = 5381;
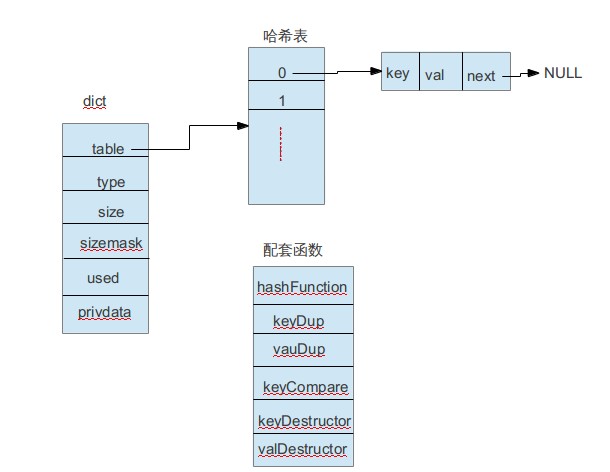
/* 创建字典,初始化除table之外的其他元素,此时哈希表是空的 */ /* Create a new hash table */ dict *dictCreate(dictType *type, void *privDataPtr) { dict *ht = _dictAlloc(sizeof(*ht));
_dictInit(ht,type,privDataPtr); return ht; }
创建字典,调用_dictAlloc分配内存, 调用_dictInit初始化字典。
2. dictResize
1 2 3 4 5 6 7 8 9 10
/* Resize the table to the minimal size that contains all the elements, * but with the invariant of a USER/BUCKETS ration near to <= 1 */ intdictResize(dict *ht)/* 将字典中哈希表的长度调到最小 */ { int minimal = ht->used;
/* Resize the table to the minimal size that contains all the elements, * but with the invariant of a USER/BUCKETS ration near to <= 1 */ int dictResize(dict *ht) /* 将字典中哈希表的长度调到最小 */ { int minimal = ht->used;
/* Expand or create the hashtable */ int dictExpand(dict *ht, unsigned long size) { /* 创建一个新的哈希表 */ dict n; /* the new hashtable */ unsigned long realsize = _dictNextPower(size), i; /* 如果给定的size小于原表中已经使用的大小,则出错 */ /* the size is invalid if it is smaller than the number of * elements already inside the hashtable */ if (ht->used > size) return DICT_ERR;
_dictInit(&n, ht->type, ht->privdata); n.size = realsize; n.sizemask = realsize-1; n.table = _dictAlloc(realsize*sizeof(dictEntry*)); /* 将哈希表中的所有指针初始化为NULL */ /* Initialize all the pointers to NULL */ memset(n.table, 0, realsize*sizeof(dictEntry*));
/* Copy all the elements from the old to the new table: * note that if the old hash table is empty ht->size is zero, * so dictExpand just creates an hash table. */ n.used = ht->used; for (i = 0; i < ht->size && ht->used > 0; i++) { dictEntry *he, *nextHe;
if (ht->table[i] == NULL) continue;
/* For each hash entry on this slot... */ he = ht->table[i]; while(he) { unsigned int h;
nextHe = he->next; /* Get the new element index */ h = dictHashKey(ht, he->key) & n.sizemask; he->next = n.table[h]; n.table[h] = he; ht->used--; /* Pass to the next element */ he = nextHe; } /* 190行的代码相当于 "h = dictHashKey(ht, he->key) % n.size" */ } /* 使用位运算可以比取模运算节省很多时间 */ assert(ht->used == 0); _dictFree(ht->table); /* 释放字典ht中的哈希表 */
/* Remap the new hashtable in the old */ *ht = n; /* 将字典n中存储的内容赋给ht指向的字典 */ return DICT_OK; }
/* Add an element to the target hash table */ intdictAdd(dict *ht, void *key, void *val) { int index; dictEntry *entry;
/* Get the index of the new element, or -1 if * the element already exists. */ if ((index = _dictKeyIndex(ht, key)) == -1) /* 获取key对应的索引 */ return DICT_ERR;
/* Set the hash entry fields. */ dictSetHashKey(ht, entry, key); /* 设置结点的各个域 */ dictSetHashVal(ht, entry, val); ht->used++; return DICT_OK; }
向目标字典中添加元素。
5. dictReplace
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
/* 将键值插入到哈希表中,不管键对应的结点在哈希表中是否已经存在 */ /* Add an element, discarding the old if the key already exists */ intdictReplace(dict *ht, void *key, void *val) { dictEntry *entry;
/* Try to add the element. If the key * does not exists dictAdd will suceed. */ if (dictAdd(ht, key, val) == DICT_OK) return DICT_OK; /* It already exists, get the entry */ entry = dictFind(ht, key); /* Free the old value and set the new one */ dictFreeEntryVal(ht, entry); dictSetHashVal(ht, entry, val); return DICT_OK; }
dictEntry *dictNext(dictIterator *iter) { while (1) { if (iter->entry == NULL) { iter->index++; if (iter->index >= (signed)iter->ht->size) break; iter->entry = iter->ht->table[iter->index]; } else { iter->entry = iter->nextEntry; } if (iter->entry) { /* We need to save the 'next' here, the iterator user * may delete the entry we are returning. */ iter->nextEntry = iter->entry->next; return iter->entry; /* 我们要把下一个结点保存起来 */ } /* 调用者有可能会删除我们返回的结点*/ } returnNULL; }
/* 返回哈希表中的一个随机结点,这对实现随机化算法很有用 */ /* Return a random entry from the hash table. Useful to * implement randomized algorithms */ dictEntry *dictGetRandomKey(dict *ht) { dictEntry *he; unsignedint h; int listlen, listele; /* 字典的哈希表未存储结点 */ if (ht->used == 0) returnNULL; do { h = random() & ht->sizemask; he = ht->table[h]; } while(he == NULL);
/* Now we found a non empty bucket, but it is a linked * list and we need to get a random element from the list. * The only sane way to do so is to count the element and * select a random index. */ listlen = 0; while(he) { he = he->next; listlen++; } listele = random() % listlen; he = ht->table[h]; while(listele--) he = he->next; return he; }